Stream 구조와 특징
자바 스트림에 대해 정리한 글입니다.
Stream API란?
스트림은 자바 8에 새로 추가된 기능이다.
Sequence of elements supporting sequential and parallel aggregate operations 순차 & 병렬 집합 연산을 지원하는 요소들의 나열
스트림은 데이터 처리 연산을 지원하는 연속된 요소들의 모음이라고 정의할 수 있다. 다음 정의를 쪼개서 하나씩 살펴보자.
연속된 요소 (Sequence of elemets)
- 연속적인 특정 데이터의 형식으로 이루어진 데이터의 처리방법을 의미한다.
데이터 처리 연산(aggregate operations)
- 위에서 언급한 데이터의 처리방법을 의미한다.
- filter, map, reduce, find, match, sort와 같은 연산들이 이에 해당한다.
컬렉션과 stream 차이
스트림은 데이터 소스를 단 한번만 탐색할 수 있다.
- 반복자와 마찬가지로 한번 탐색한 요소를 다시 탐색하려면, 초기 데이터 소스에서 새로운 스트림을 만들어야 한다.
- 반복사용할 수 있어야하는 데이터 소스여야 한다. 데이터 소스가 I/O라면 반복 불가능하니, 새로운 스트림을 만드는 것이 불가능하다.
Stream 특징
1. 선언형
- 스트림을 이용하면 선언형 (연산의 결과로 무엇을 하기를 바라는지 나타내는)프로그래밍 방식으로 컬렉션 데이터를 처리할 수 있다.
2. 내부 반복
사용자가 반복자를 사용하여 직접 요소를 반속하는 것을 외부 반복이라고 한다. 반복을 알아서 처리하고, 결과 스트림 값을 어딘가에 저장해주는 것을 내부 반복이라고 한다.
- 반복자(for, while)를 이용해서 명시적으로 요소를 반복하는 컬렉션과는 다르게, 내부 반복을 지원한다.
- 이에 대한 연산 방법을 숨긴다.
3. 병렬 처리
- 멀티스레드 코드를 구현하지 않아도 데이터를 투명하게 병렬로 처리할 수 있다.
4. 파이프라이닝
대부분의 스트림 연산은 스트림 연산끼리 연결할 수 있도록 디자인되었다. 따라서 연산의 결과는 스트림 자신을 반환하도록 되어있다. 파이프라인은 데이터 소스에 적용하는 질의 같은 존재이다. 덕분에 lazyness, short-circuiting과 같은 성능 최적화를 얻을 수 있다.
lazuness
- 데이터를 언제 계산하느냐가 컬렉션과 스트림의 가장 큰 차이다.
- 컬력센은 현재 자료구조가 포함하는 모든 값을 메모리에 저장하는 자료구조이다.
- 즉, 컬렉션의 모든 요소는 컬렉션에 추가하기 전에 계산되어야 한다.
short-circuiting
- and 연산에서 하나라도 거짓이면, 나머지 표현식에 대한 평가를 중지하고 결과를 반환
- 전체 스트림을 처리하지 않아도 결과를 반환할 수 있는 연산 -> limit, matching
반면 스트림은 이론적으로 요청할 때만 요소를 계산하는 자료구조다. -> 스트림에 요소를 추가하거나, 스트림에서 요소를 제거할 수 없다. 게으르게 만들어지는 컬력센과 같다.
이러한 특성으로 인해 결과적으로 생산자 - 소비자 관계를 형성한다. 인터넷 스트리밍을 예시로 들기 적합하다.
- 선언형 : 간결하고 가독성이 좋음
- 조립 가능 : 유연하게 대처 가능
- 병렬화 : 성능상의 이점
Stream 구조
Stream은 기본적으로 데이터 소스를 필요로 한다.
주어진 데이터 소스에 대해 연산처리를 지원해주는데 연산처리를 담당하는 스트림 오퍼레이션은 두 부분으로 나뉜다.
- intermediate (중간 작업)
- terminal (종단 작업)
그리고 이 2가지를 결합하여서 스트림 파이프 라인을 형성한다. 그림으로 나타내면 다음과 같다.
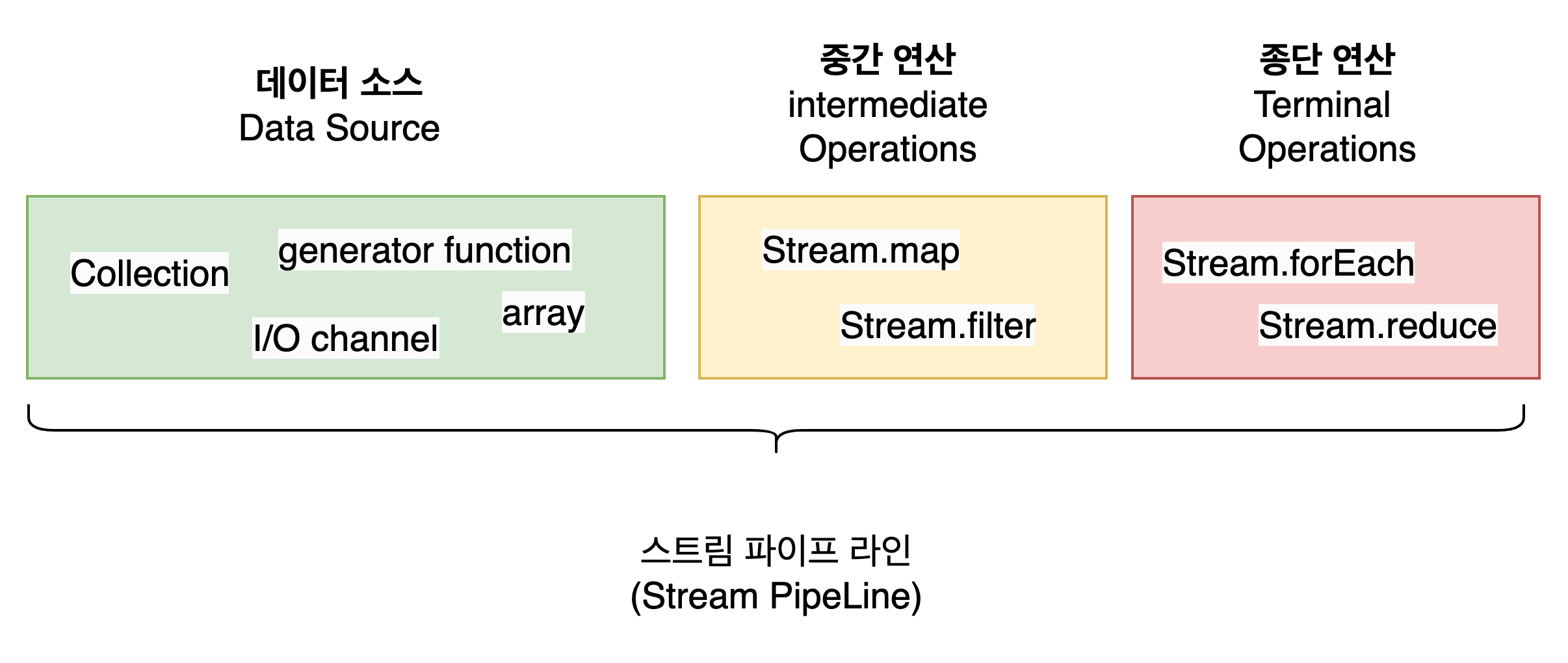 스트림 구조
스트림 구조
데이터 소스 (Data Source)
데이터 소스는 스트림을 만들 수 있는 대상(target)을 의미한다. 다음과 같은 형태들이 데이터 소스가 될 수 있다.
- Collection에서:
stream()및parallelStream()메서드를 사용하여Collection인터페이스를 구현한 데이터 구조(예:List,Set)로부터 스트림을 생성한다. - 배열(Array)에서:
Arrays.stream(Object[])메서드를 통해 배열을 스트림으로 변환한다. 이 방법은 배열 기반의 데이터를 스트림으로 처리할 때 유용하다. - Stream 클래스의 정적 팩토리 메서드:
Stream.of(Object[]): 여러 개의 객체를 스트림으로 생성한다.IntStream.range(int, int): 특정 범위의 정수를 포함하는 스트림을 생성한다.Stream.iterate(Object, UnaryOperator): 초기값과 반복 규칙을 기반으로 무한 스트림을 생성한다.
- 파일 라인(Line)에서:
BufferedReader.lines()메서드를 사용하여 파일의 각 줄을 스트림으로 가져온다. 이를 통해 파일 데이터를 효율적으로 처리할 수 있다. - 파일 경로(Path)에서:
Files클래스의 메서드를 사용하여 파일 경로의 스트림을 생성한다. 예를 들어 디렉토리 내 파일 목록을 스트림으로 처리할 때 유용하다. - 난수(Random Number) 스트림:
Random.ints()메서드를 통해 난수로 구성된 스트림을 생성한다. 이는 무작위 데이터 처리가 필요한 경우에 활용된다. - 기타 JDK 메서드:
BitSet.stream(): 비트 집합(BitSet)의 값을 스트림으로 변환한다.Pattern.splitAsStream(CharSequence): 문자열 패턴을 기준으로 나눈 결과를 스트림으로 반환한다.JarFile.stream(): JAR 파일 내 엔트리를 스트림으로 제공한다.
중간 연산 (Intermediate Operations)
중간 연산의 특징은 연산의 반환 타입이 스트림이라는 것이다. 그리고 이 연산들은 실제 스트림을 적용하는 원본 데이터 소스를 건들이지 않는다. 단지 원본 데이터에서 연산을 수행한 결과들을 리턴하는 것 뿐이다. 따라서 중간 연산들을 연결하여 질의를 만들 수 있다.
그리고 중간 연산들은 lazy 한 특성을 가지고 있다. 연산을 종단 연산 terminal이 호출되기전 시점까지 미루는 특징을 가지고 있다. 따라서 뒤에 종단 연산이 존재하지 않는다면, 중간 연산은 아무런 연산도 수행하지 않는다.
Stream<T> filter(Predicate<? super T> predicate 중간연산은 없어도 되고, 다수의 여러 중간연산이 존재해도 무방하다.
종단 연산(Terminal Operations)
종단 연산은 스트림 파이프라인에서 결과를 도출하는 역할을 맡는다. 때문에 종단 연산은 새로운 Stream을 리턴하지 않는다. 스트림이 종료되는 시점으로 연산의 결과 타입이 리턴된다.
한개의 종단 연산만 가능하다.
종단 연산을 호출하기 전까지는 데이터소스에서 무엇도 선택되지 않는다. 그러므로 출력결과도 없다. 즉, 종단 연산이 호출되지 전까지는 메서드의 호출이 저장되는 효과가 있다.
filter나, sorted, map, collect와 같은 연산은 고수준 빌딩 블록으로 이루어져, 특정 스레딩 모델에 제한되지 않고, 자유롭게 어떤 상황에서든 사용할 수 있다. 결과적으로 데이터 처리 과정을 병렬화하면서 스레드와 락을 걱정할 필요가 없다.
Stream 연산 활용
스트림 연산 : 상태 없음과 상태 있음.
Filtering
- predicate
- distinct Slicing
- predicate
- 처음 몇개 무시 : skip
- 특정 크기로 줄이기 Mapping (특정 데이터를 선택하는 작업) 인수로 제공된 함수가 각각의 요소에 적용되며, 적용된 결과가 새로운 요소로 반환된다.(변환보다는 새로운 값을 만든다)
- map, flatMap 검색과 매칭
- , , , findFirst, findAny 등 다양한 유틸리티 메서드 제공
- anyMatch(predicate) 적어도 한 요소와 일치하는지 확인
- allMatch (predicate) 모든 요소와 일치하는지 검사
- noneMatch, allMatch와 반대 연산을 수행 요소 검색
- findAny : 현재 스트림에서 임의의 요소를 반환
Optional<T>를 반환
리듀싱
- 요소의 합 등, 값을 단일된 결과로 리턴할때까지 반복하는 연산
- map-reduce 기법
1
2
3
4
Integer dishCount = menu.stream()
.map(dish -> 1)
.reduce(0, Integer::sum);
System.out.println("dishCount = " + dishCount);
리듀스 메서드의 장점
숫자형 스트림
Integer를 기본형으로 언박싱해야함. 스트림 API 박싱 비용을 피할 수 있도록 기본형 특화 스트림을 제공함.
boxed 메서드로 숫자형 스트림 <-> 객체 스트림으로 변환이 가능함.
1
2
3
4
5
6
7
8
IntStream mapToInt(ToIntFunction<? super T> mapper);
public interface IntStream extends BaseStream<Integer, IntStream> {
...
IntStream map(IntUnaryOperator mapper);
...
Stream<Integer> boxed();
}
boxed 찾아가보니
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
abstract class IntPipeline<E_IN>
extends AbstractPipeline<E_IN, Integer, IntStream>
implements IntStream {
...
@Override
public final Stream<Integer> boxed() {
return mapToObj(Integer::valueOf, 0);
}
...
private <U> Stream<U> mapToObj(IntFunction<? extends U> mapper, int opFlags) {
return new ReferencePipeline.StatelessOp<Integer, U>(this, StreamShape.INT_VALUE, opFlags) {
@Override
Sink<Integer> opWrapSink(int flags, Sink<U> sink) {
return new Sink.ChainedInt<U>(sink) {
@Override
public void accept(int t) {
downstream.accept(mapper.apply(t));
}
};
}
};
}
}
기본형 OptionalInt
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
OptionalInt maxCalories = menu.stream()
.mapToInt(Dish::getCalories)
.max();
---
@jdk.internal.ValueBased
public final class OptionalInt {
...
private static final OptionalInt EMPTY = new OptionalInt();
private final boolean isPresent;
private final int value;
private OptionalInt() {
this.isPresent = false;
this.value = 0;
}
}
- 값이 없는 경우는 OptionalInt.empty가 반환됨.
- OptionalInt는
booleanisPresent 과intvalue를 가지고 있음.
피타고라스 정리
1
2
3
4
5
6
7
8
9
Stream<int[]> pythagoreanTriples = IntStream.rangeClosed(1, 100).boxed()
.flatMap(a ->
IntStream.rangeClosed(a, 100)
.filter(b -> Math.sqrt(a * a + b * b) % 1 == 0)
.mapToObj(b -> new int[]{a, b, (int) Math.sqrt(a * a + b * b)})
);
pythagoreanTriples.limit(5)
.forEach(t-> System.out.println(t[0] + " " + t[1] + " " + t[2]));
- 내부 스트림: 각
a에 대해 여러b값을 처리하여Stream<int[]>을 반환하는 작은 스트림. - 평탄화: 이러한 여러 내부 스트림을 모두 하나의 스트림으로 합치는 과정. 이로 인해
Stream<Stream<int[]>>이 아니라, 하나의 연속된Stream<int[]>이 된다
Stream 특징 정리
다시 스트림의 특징을 정리하자면 다음과 같다.
- 스트림은 반복문과 같이 유한한 사이즈를 같지 않는다. 무제한의 사이즈를 가질 수 있다.
- 길이가 정해져 있지 않은 데이터소스의 연산을 수행할 수 있다.
limit(n)orfindFirst()과 같은 Short-circuiting 연산들로 제한할 수 있다.
- 저장소가 아님
스트림은 데이터를 저장하는 자료구조가 아니다. 대신, 데이터 구조(Array, Collection), 생성 함수, I/O 채널 등과 같은 소스로부터 요소를 전달받아 연산 파이프라인을 통해 처리한다. - 함수형 특성
스트림에서 수행되는 연산은 결과를 생성하지만 원본 데이터를 수정하지 않는다.
예를 들어, 컬렉션에서 얻은Stream에 필터링 연산을 적용하면 필터링된 요소를 제외한 새로운Stream이 생성되며, 원본 컬렉션의 데이터는 변경되지 않는다. - 지연(lazy) 연산 지원
스트림의 많은 연산(필터링, 매핑, 중복 제거 등)은 지연 평가 방식으로 구현될 수 있어 최적화가 가능하다.
예를 들어, “세 개의 연속된 모음을 가진 첫 번째 문자열 찾기”와 같은 작업은 모든 입력 문자열을 검사하지 않아도 된다.
스트림 연산은 중간 연산(Stream을 반환)과 최종 연산(값 또는 부작용을 생성)으로 나뉘며, 중간 연산은 항상 지연 평가된다. - 소모성
스트림의 요소는 스트림이 존재하는 동안 한 번만 접근할 수 있다.
이는Iterator와 유사하며, 동일한 소스의 요소를 다시 방문하려면 새로운 스트림을 생성해야 한다.